Unstructured data in documents, chats & tickets is making up a higher percentage of total data-footprint in organizations. Transactional databases and customer tables might still be the predominant form of system-of-record but generally these are also being fed from and used alongside SaaS platforms. Understanding what data an organization possesses is the first step towards harnessing it. This makes data classification even more important from a risk management perspective.
For security teams, data inventory is not just database records but sum total of all the various systems under the organizational umbrella. It just takes one leaked or stolen file to end up with a hefty fine that is splashed across the news headlines. Risk mitigation is critical. This is where data classification comes in.
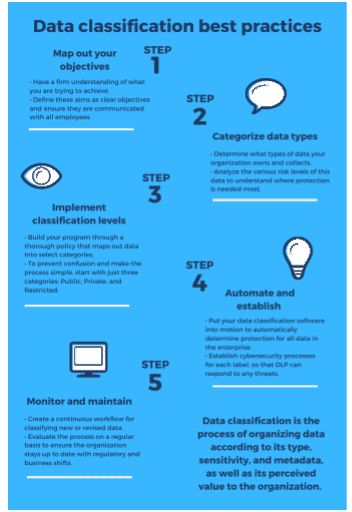
Data classification is the process of organizing data according to its type, sensitivity, and metadata, as well as its perceived value to the organization. By organizing data on such parameters, it allows organization to:
- Mitigate risk in case data is altered, deleted, or stolen
- Comply with industry standards such as the HIPAA, DSS, or the EU’s GDPR
- Implement data access controls and come up with data protection policies
- Improve visibility and control over the vast amount of stored and produced
A strong data classification process is an essential building block for effective data loss prevention (DLP). The two tend to work together. Here’s how:
An employee goes to share a highly confidential file with a third-party user over email. The enterprise’s data classification tool marks this as a red flag so that the DLP tool can take immediate action. DLP will either redact the sensitive file from the email or prevent it from being sent all together. At the same time, it will also flag the suspicious activity to the security team so they can investigate further.
Data classification vs data indexing
It’s worth noting that, while data classification is closely related to data indexing, there is one crucial difference: data classification doesn’t necessarily generate a searchable index.
Unlike data indexing, the search results for classification only list the file and the pattern it matched. It doesn’t store an index of the file’s content.
However, some data classification software can generate searchable indexes to fulfill data subject access requests (DSAR), as well as right to be forgotten requests under the GDPR.
Discovering your data
For data classification to be impactful, you first need to know where your data is, the volume, and the context. Today, businesses hold vast amounts of information that is spread across different platforms and repositories, including cloud storage services, collaboration tools, files like PDFs and emails, and databases.
To find all this data, you must conduct a comprehensive data discovery assessment. Here, automated tools can assist you – particularly if your data is scattered across the cloud and on-premises locations.
What are the 3 types of data classification?
Once you’ve discovered your data, it’s time to classify it. There are three main approaches for this:
- Context-based:Uses contextual analysis to gauge the data’s sensitivity, looking at factors such as who is accessing the file, where they are sharing it and the time of day of access.
- Content-based:Rather than looking at the context around the file, this inspects the data itself, looking for sensitive information. This relies on techniques such as regular expression and fingerprinting.
- User-based: Both of the above rely on degrees of automation while this process is manual. It relies on individual users to classify sensitive documents as they create or edit them.
Manual vs automated data classification
As you can see above, data classification falls into two buckets: automated or manual. Automated classification can scale quickly, while a manual approach will give a direct touch to the data. Here are the pros and cons of both.
Manually defined data classification is when data is manually tagged by users. While human eyes may technically be better at judging which content is sensitive, this method also requires a lot more time, effort and resources, as users will need to be trained in data classification levels. Plus, if your enterprise has large amounts of historical data, classification can be a laborious task for your team.
It’s also worth noting that the manual technique is not a bulletproof solution. It has its own security risks, including:
- Placing a high amount of trust in employees to classify data with integrity, without considering the potential of malicious insiders.
- There is always the danger of human error, which could lead to files being tagged incorrectly and a consequent data leak.
- Because data is always in motion, this manual, stagnant method does not tend to account for contextual changes in data sensitivity. As one Forbes article put, “What is important today might not be important tomorrow. What is not sensitive today might become sensitive in the future.”
Automated data classification, on the other hand,uses apps or tools to automate the process. Such solutions typically use a file parser to read the content of files, and a string analysis system to match the content to defined search parameters.
This approach is much faster, more efficient, and scalable for immense databases. It also reduces the likelihood of the insider threat. However, just like the manual process, it has its limitations, such as:
- A tendency to produce false positives.
- Accuracy is affected by the quality of the file parser used.
- Can be a pricey route for smaller organizations.
For optimum performance, we recommend that mid-sized organizations and above take a hybrid approach to classification, opting for automation for the bulk of data, and then deploying manual intervention in instances where data is difficult to classify.
Furthermore, to reduce false positives and improve the precision of automation, the security team should regularly review and fine-tune the rules for data classification.
Choosing a data classification solution
The data classification market is crowded and many vendors – from cloud storage providers to cybersecurity businesses – offer these capabilities as part of their product offers. This means it can be overwhelming to find the right provider, at the right cost, and with adequate protections.
It’s important to remember that there is no one-size-fits-all. The solution that’s best for your business will depend on factors such as the size of your organization, where most of your sensitive data is stored and the compliance standards you need to adhere to.
To help you narrow down your search, there are some important features that you should look for in data classification software:
- Indexing feature:This allows you to identify sensitive terms, without having to recrawl the data.
- Flexible taxonomy:The software should make it easy for users to modify search terms and rules, and create new ones.
- Compound term search support:This helps to minimize false positives and negatives.
- Sensible workflow:A smartly designed solution should automatically take actions, such as moving sensitive files away from a public share.
- Coverage support:Check if it supports both structured and unstructured data, as well data sources that may not be on-premises (i.e. in the cloud)
Best practices for successful implementation
Once you’ve chosen your solution, it’s time for deployment. To maximize success, here are some best practices:
- Map out your Objectives
- Categorize data types
- Implement classification levels
- Automate and establish
- Monitor and maintain